母集団と標本の違いとは?調査設計の基礎をプロが解説

母集団と標本は、あらゆる調査の出発点となる概念です。「母集団=調べたい集団の全体」と辞書的に覚えるだけでは、調査の現場では不十分です。母集団をどう定義するかという調査設計の“技術”こそが、調査結果の信頼性を左右します。本記事では、母集団と標本の基本から、プロが実務でどう母集団を定義しているかまで、65年以上の調査実績を持つ株式会社日本リサーチセンター(NRC)が、基本定義から実務での設計手法までを解説します。
- 母集団とは「調査によって結論を導きたい対象の全体」であり、標本はその一部を抽出したもの
- 「ターゲット母集団」と「調査母集団」の区別が、調査精度を左右する最大のポイント
- 母集団の定義を誤ると、いくらサンプルを増やしても正しい結論は得られない
- 1936年の米国大統領選におけるリテラリー・ダイジェスト事件は、母集団設計の失敗が招いた歴史的教訓
- 「第1回 ネットリサーチの落とし穴」
- 「第2回 標本調査と全数調査の違いとは?具体例でわかりやすく解説|調査のプロが教える使い分け」
- 今回はココ
「第3回 母集団と標本の違いとは?調査設計の基礎をプロが解説」
母集団とは?標本とは?基本の定義をわかりやすく解説

統計調査の設計は、「誰について知りたいのか」を決めるところから始まります。ここで登場する2つの基本概念が、母集団と標本です。
母集団の定義──「知りたい対象の全体」
母集団(population)とは、調査によって特徴を明らかにしたい対象の全体集合です。
「日本の全有権者」「自社商品を過去1年以内に購入した全顧客」「東京都内に住む20代女性の全員」──調査の目的によって、母集団は異なります。母集団は自然に存在する固定概念ではなく、調査者が調査目的に応じて「設定」するものです。この点が重要です。
たとえば「若者の消費意識」を調査するとしましょう。「若者」とは15歳から29歳でしょうか。それとも18歳から34歳でしょうか。この範囲を決めることが、母集団を定義する行為そのものです。
標本(サンプル)の定義──母集団から抽出した一部
標本(sample)とは、母集団の中から選び出された一部の集団です。
母集団の全員を調べる「全数調査」は、コスト・時間・物理的制約から実施が難しいケースが大半です。そこで母集団から一部を抽出し、その結果から全体の傾向を統計的に推定します。これが標本調査の考え方です。
標本調査と全数調査の使い分けについては、前回の記事「標本調査と全数調査の違いとは?」で詳しく解説しています。
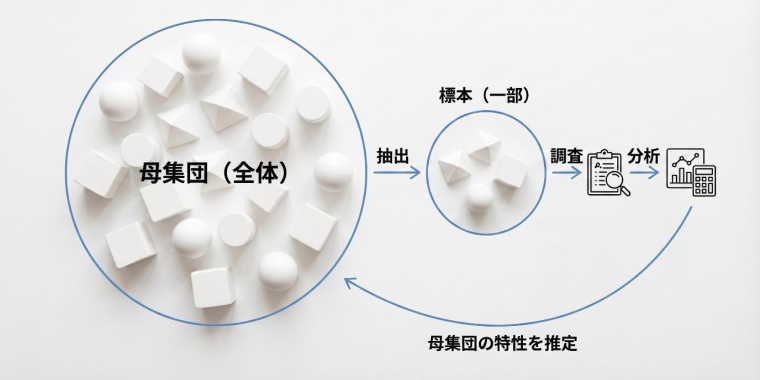
母集団(全体)→ 抽出 → 標本(一部)→ 調査 → 分析 → 母集団の特性を推定
| 比較項目 | 母集団 | 標本 |
|---|---|---|
| 定義 | 調査で結論を導きたい対象の全体 | 母集団から抽出した一部 |
| サイズ | 数千〜数億(調査目的による) | 数百〜数千が一般的 |
| 調査方法 | 全数調査(コスト大) | 標本調査(コスト小) |
| 分析結果 | 母集団の「真の値」(パラメータ) | 母集団の「推定値」(統計量) |
| 具体例 | 日本の全有権者(約1億人) | 世論調査の回答者(1,000〜3,000人) |
ここで押さえておきたいのは、標本はあくまで母集団の「代理」であるという点です。標本から得た結果を母集団全体に当てはめるには、標本が母集団を正しく反映している必要があります。では、「正しく反映する」ための出発点はどこにあるのでしょうか。
なぜ母集団の「定義」が調査の成否を分けるのか

ターゲット母集団と調査母集団──知っておくべき2つの概念
調査の現場で重要になるのが、ターゲット母集団と調査母集団の区別です。
- ターゲット母集団(target population): 本当に知りたい対象の全体。調査の理想形です。
- 調査母集団(survey population): 実際に調査でアクセスできる範囲。調査の現実です。
この2つは、しばしば「ズレ(カバレッジ誤差)」が生じます。
| 調査目的 | ターゲット母集団(理想) | 調査母集団(現実) | ズレの正体 |
|---|---|---|---|
| 国民全体の意識調査 | 日本在住の全成人 | ネット調査パネル登録者 | ネット非利用者・未登録者が抜け落ちる |
| 自社商品の満足度調査 | 商品購入者全員 | メール配信リスト上の購入者 | メールアドレス未登録の購入者が抜ける |
| 高齢者の健康意識調査 | 65歳以上の全住民 | 電話帳に掲載された65歳以上 | 電話帳に載っていない人が抜ける |
このズレが、統計学でカバレッジ誤差と呼ばれる問題です。ターゲット母集団の中に「調査でアクセスできない人」がいると、その人たちの声は結果に反映されません。カバレッジ誤差の具体的な影響については、第1回記事「ネットリサーチの落とし穴」で詳しく解説しています。
母集団の定義が曖昧だとなぜ問題か──3つの失敗パターン
パターン1:対象が広すぎる
「日本人全体の意識を知りたい」と設定したものの、実際にはネット調査パネルでしか調査しなかった。
→パネル登録者はネットを使う層に限られるため、高齢者やデジタル機器に不慣れな層の声が欠落します。
パターン2:対象が狭すぎる
「顧客満足度」を知りたいのに、自社アプリの利用者だけに調査した。
→アプリを使わない顧客や、すでに離反した元顧客の声が抜け落ち、実態よりも好意的な結果が出てしまいます。
パターン3:定義が不明確
「若者の消費意識」を調べるとしたとき、「若者」の範囲を15歳から29歳とするか、18歳から34歳とするかで、結果はまったく異なります。定義があいまいなまま調査を進めると、分析段階で解釈に困ることになります。
【実務の視点】NRCが調査設計で最初に行うこと
NRCが調査設計に着手する際、最初に行うのは「母集団の明文化」です。具体的には、次の3つの問いに答えることから始めます。
- 何を知りたいのか──調査の目的を明確にする
- 誰について知りたいのか──ターゲット母集団を定義する
- その全体にどうアクセスするか──調査母集団(抽出フレーム)を選定する
母集団を正しく定義できれば、抽出方法・調査手法・サンプルサイズ(n数)は論理的に決まります。逆に言えば、母集団の定義があいまいなまま「何人に聞けばよいですか?」と問うのは、行き先を決めずに「何時間歩けばよいですか?」と問うのと同じです。
歴史に学ぶ──母集団の定義を誤った1936年のアメリカ大統領選挙調査

母集団の定義がいかに重要か。それを劇的に示したのが、1936年のアメリカ大統領選挙予測調査です。
リテラリー・ダイジェスト誌の予測はなぜ外れたのか
当時アメリカで最も影響力のある雑誌だった「リテラリー・ダイジェスト」は、大統領選の予測調査を大々的に実施しました。調査票を約1,000万人に郵送し、約240万人から回答を回収。結果は「共和党のランドン候補が勝利する」という予測でした。
ところが、実際に勝利したのは民主党の現職ルーズベルト大統領。しかも得票率60%を超える圧勝でした。
その原因は、サンプルサイズではありません。240万人は途方もない数です。問題は調査対象者の抽出にありました。リテラリー・ダイジェストは自社の購読者リスト、電話帳、自動車の登録名簿から送付先を選びました。1930年代のアメリカで雑誌を購読し、電話を所有し、自動車を持っている層は、当時の富裕層や中産階級に偏っていました。
つまり、リテラリー・ダイジェストが設定した調査母集団は「アメリカの有権者全体」ではなく、「比較的裕福な有権者」だったのです。大恐慌後の経済政策が最大の争点だった選挙において、この偏りは致命的でした。
一方、ギャラップはわずか5万人で正確に予測した
同じ選挙で、調査実務家のジョージ・ギャラップは統計的な代表性を確保する科学的サンプリングを採用しました。調査した人数はわずか約5万人。リテラリー・ダイジェストの20分の1以下です。しかしギャラップは、ルーズベルトの勝利を正確に予測しました。
この結果が世界に示したのは、サンプルの「量」ではなく「母集団をどれだけ正確に反映しているか」が調査精度を決める、という原則です。240万人の偏ったサンプルより、5万人の代表性あるサンプルのほうが正確でした。
NRCは(GIA:Gallup International Association)の唯一の日本代表メンバーとして、この科学的調査の伝統を受け継いでいます。NRCが確率抽出に基づく訪問調査を今も実施し続けている理由は、まさにこの原則にあります。
母集団と標本の違いを整理する【比較表】

ここで、母集団と標本の違いを5つのポイントで整理します。
| ポイント | 母集団 | 標本 |
|---|---|---|
| ① 定義 | 調査の対象全体 | 母集団から抽出した一部 |
| ② 役割 | 真の特性(パラメータ)を持つ | 特性を推定するための情報源 |
| ③ サンプルサイズの決め方 | 調査目的で設定(固定) | 必要な精度から統計的に算出 |
| ④ 代表性の要件 | 正しく定義されていることが前提 | 母集団を正しく反映していることが前提 |
| ⑤ よくある誤解 | 「大きいほど正確」→ 誤り | 「多いほど正確」→ 条件つきで正しい |
⑤の「よくある誤解」は重要です。
サンプルサイズを増やせば標本誤差は小さくなります。これは統計学の事実です。しかし、母集団の定義が間違っていれば、いくらサンプルを増やしても結果は改善しません。リテラリー・ダイジェストの240万人がその証拠です。
逆に、母集団が正しく定義され、母集団の縮図を構成する科学的なサンプリングが行われていれば、比較的少数のサンプルでも高い精度を実現できます。ギャラップの5万人がその証拠です。
サンプルの「量」よりも、母集団の「定義の質」が調査精度を決める。 これが本記事で最もお伝えしたいメッセージです。
調査の現場で母集団と標本をどう設計するか

母集団の定義から標本設計までの3ステップ
ステップ1:母集団を定義する
「誰の」「何を」知りたいかを明確にし、ターゲット母集団を設定します。「全国の20代〜40代の会社員で、過去3か月以内にオンラインで食品を購入した人」のように、条件を具体的に絞り込みます。
ステップ2:抽出フレーム(名簿)を選ぶ
ターゲット母集団にアクセスするための手段を選びます。自社の顧客データベース、ネット調査パネルなど、どのフレームを使うかによって調査母集団が決まります。ここでターゲット母集団とのズレ(カバレッジ誤差)が発生しないか、事前に評価することが重要です。
ステップ3:サンプルサイズと抽出方法を決める
許容できる誤差の幅と信頼水準(通常95%)から、必要なサンプルサイズを統計的に算出します。全国規模の消費者調査であれば1,000〜2,000サンプルが一般的な目安です。
無作為抽出はなぜ重要か──「代表性」を確保する唯一の方法
標本が母集団を正しく反映するために不可欠なのが、無作為抽出(ランダムサンプリング) です。
無作為抽出とは、母集団のすべての構成員が等しい確率で選ばれるように抽出する方法です。この手続きにより、標本の代表性が統計的に確保されます。代表性があるからこそ、標本の結果を母集団全体に当てはめる「一般化」が可能になるのです。
NRCが実施するNOS(日本リサーチセンター・オムニバス・サーベイ)では、住民基本台帳から全国200地点で対象者を確率抽出し、調査員が一軒一軒訪問することで1,200票を回収しています。ネット調査であれば短時間で回収できるサンプル数でも、あえて訪問調査を実施するのは、「自らアンケートに応じない人」を含めた偏りの少ないデータを得るためです。
無作為抽出の具体的な方法(単純無作為抽出、層化抽出、多段抽出など)については、次回以降の記事で詳しく解説する予定です。
ネット調査における母集団の考え方
現在、マーケティング調査の主流であるネット調査では、母集団の考え方に特有の注意点があります。
ネット調査パネルの母集団は「パネルに登録した人」であり、日本国民全体ではありません。パネル登録者は「自ら登録した人」に限られるため、ターゲット母集団と調査母集団の間にはカバレッジ誤差と自己選択バイアスが構造的に内在します。この点は、第1回記事「ネットリサーチの落とし穴」で詳しく解説しました。
ネット調査が「使えない」という話ではありません。重要なのは、調査母集団の限界を認識したうえで結果を解釈することです。NRCでは、ネット調査だけでなく訪問・電話・郵送を組み合わせる「ミックスモード」を採用し、ターゲット母集団により近いデータを取得する手法も提案しています。
まとめ|母集団の「正しい定義」が調査の精度を決める

本記事の要点を整理します。
- 母集団とは、調査で結論を導きたい対象の全体。標本は、母集団から抽出した一部
- 母集団の定義は調査設計の出発点であり、最も重要なステップ
- ターゲット母集団(理想)と調査母集団(現実)のズレを認識することが、バイアスのない調査への第一歩
- サンプルの「量」より母集団の「定義の質」が精度を決める──リテラリー・ダイジェストの240万人よりギャラップの5万人が正確だった
- ネット調査ではパネル登録者が調査母集団となるため、ターゲット母集団とのズレに注意が必要
調査を設計する立場にある方は、「何人に聞くか」の前に「誰について知りたいのか」を明確にすることから始めてみてください。それが、信頼できる調査結果への最も確実な一歩です。
「どの手法で調査すべきか」「標本設計をどう組めばよいか」──NRCは訪問・郵送・ネットの全手法を自社で運用しており、目的に応じた最適な調査設計をワンストップでご提案できます。
調査設計についてのご相談は、NRC(日本リサーチセンター)までお気軽にお問い合わせください。
次回は、母集団から標本を正しく抽出するための方法──「無作為抽出」の具体的な手法を解説します。
株式会社日本リサーチセンター
株式会社日本リサーチセンターは、1960年設立の老舗総合調査会社です。
長年の経験と実績を活かし、オフラインからオンラインまで多様な調査手法に対応。世界60か国以上の調査機関との連携により、海外調査も強みとしています。マーケティングリサーチから世論調査まで幅広い顧客の課題解決を支援します。



